
Amazon Connectの通話データをAmazon Bedrockで分析し、コールリーズンを自動分類・集計する仕組みの構築してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
Amazon Connect アドベントカレンダー 2024、12日目の記事です!
クラスメソッドとギークフィードさん、クラウドビルダーズさん、ネットプロテクションズさん、AWS Japanさんの有志が募ってチャレンジしている企画になります。
(アドベントカレンダーのカレンダー一覧はこちら↓)
はじめに
Amazon Connectでの通話データをAmazon Bedrockで分析し、コールリーズン(問い合わせ理由)を自動でカテゴリ別に毎日分類・集計してCSV出力する仕組みを構築してみました。
Amazon Connect Contact Lensには、1回のお問い合わせごとに通話内容を文字起こしする機能があります。
その文字起こし内容と生成AIを組み合わせることで、通話内容がどのカテゴリーに該当するかを分析できます。
コールリーズンは、顧客が企業に連絡する目的や背景を把握するための重要な情報です。
これを分析することで、顧客のニーズや課題を明確にし、サービスの改善や効率的な対応が可能になります。
また、頻出する問い合わせ内容を特定することで、FAQの充実やプロセスの最適化を図ることができ、顧客満足度の向上やコスト削減にもつながります。
本記事の構成は以下のとおりです。
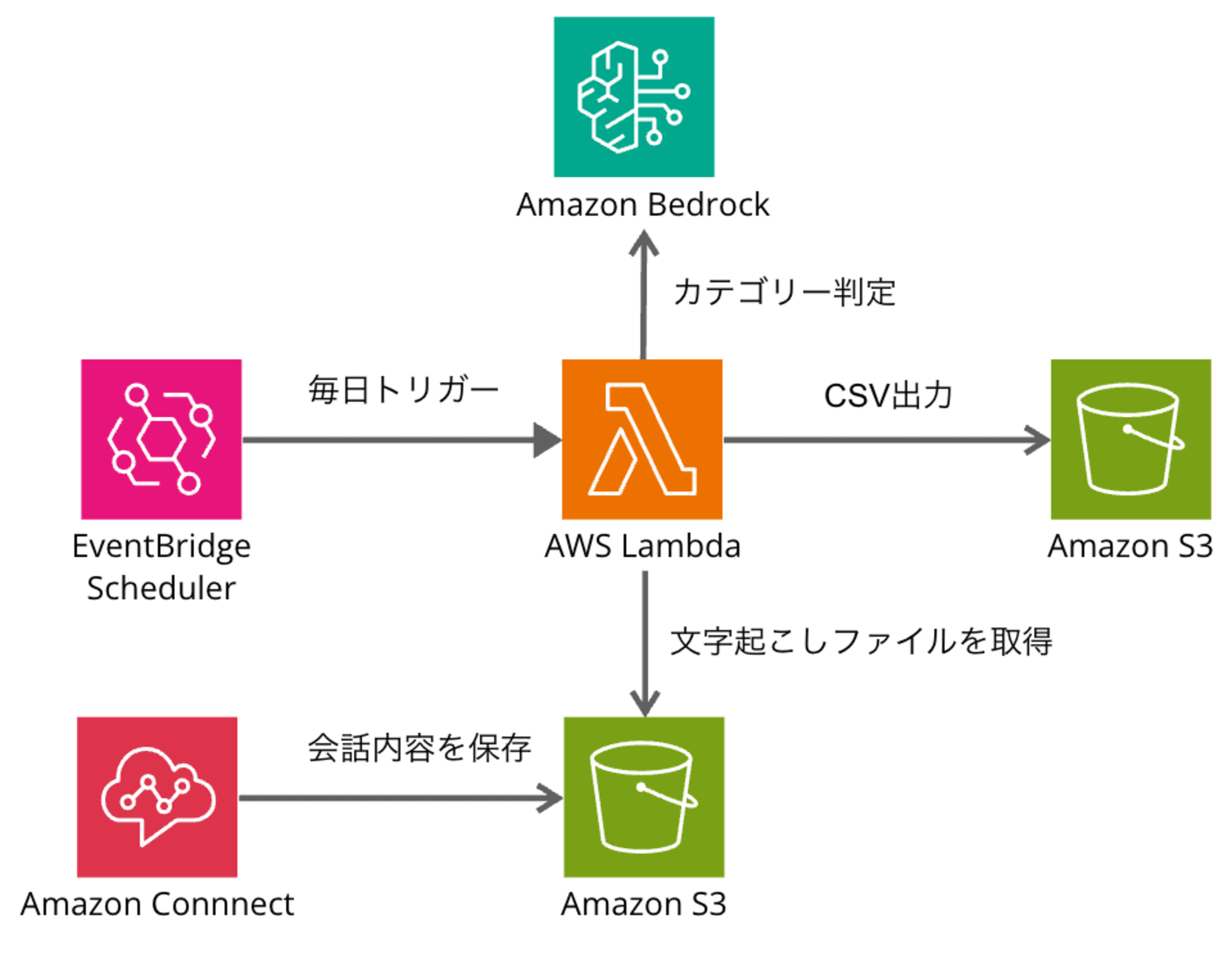
処理の流れは以下のようになります。
- Connect Contact Lensを使用して通話内容を文字起こしし、S3バケットに保存します。
- Contact Lensを有効化している場合、通話内容は自動的に保存されます。
- Amazon EventBridge Schedulerを使用して、1日1回Lambdaを起動します。
- Lambdaは、前日の全ての通話内容をS3バケットから取得し、Bedrockを使用して各お問い合わせをカテゴリー判定します。
- さらにLambdaは、全てのお問い合わせ内容をカテゴリー判定した後、集計結果をCSV形式でS3バケットに保存します。
前提条件
- Connectインスタンスは作成済みで、Contact Lensが有効化され、S3バケットに会話内容が保存されていること。
- CSV保存用のS3バケットが作成済みであること。
- Amazon Bedrockが利用可能な状態に設定されていること。
Lambdaを構築
以下の設定を使用してLambdaを作成します。
- ランタイム: Python 3.13
- タイムアウト: 20秒
- IAMロールに付与するポリシー
- AWSLambdaBasicExecutionRole
- AmazonBedrockFullAccess
- AmazonS3FullAccess
TRANSCRIPTION_BUCKETとOUTPUT_BUCKETは各自変更ください。
import boto3
import csv
import json
from datetime import datetime, timedelta
from zoneinfo import ZoneInfo
from collections import Counter
import io
MODEL_ID = 'anthropic.claude-3-5-sonnet-20240620-v1:0'
s3 = boto3.client('s3')
TRANSCRIPTION_BUCKET = 'amazon-connect-xxxxxxxx'
OUTPUT_BUCKET = 'xxxxx'
CATEGORIES = [
"商品関連",
"請求・支払い関連",
"予約・キャンセル関連",
"技術サポート関連",
"会員情報関連",
"その他"
]
def call_bedrock_model(prompt):
client = boto3.client('bedrock-runtime')
response = client.converse(
modelId=MODEL_ID,
messages=[{"role": "user", "content": [{"text": prompt}]}],
inferenceConfig={"maxTokens": 1000, "temperature": 0}
)
return response['output']['message']['content'][0]['text']
def generate_yesterday_s3_prefix():
return (datetime.now(ZoneInfo("UTC")) - timedelta(days=1)).strftime('Analysis/Voice/%Y/%m/%d/')
def list_files_in_s3_prefix(bucket_name, prefix):
response = s3.list_objects_v2(Bucket=bucket_name, Prefix=prefix)
return [content['Key'] for content in response.get('Contents', []) if content['Key'] != prefix]
def fetch_s3_file_content(bucket_name, file_key):
print(f"S3 Key:{file_key}")
response = s3.get_object(Bucket=bucket_name, Key=file_key)
data = response['Body'].read().decode('utf-8')
transcript = json.loads(data).get('Transcript', [])
return [entry['Content'] for entry in transcript if entry.get('ParticipantId') in ['AGENT', 'CUSTOMER']]
def classify_reason_with_bedrock(transcript):
conversation_text = " ".join(transcript)
prompt = f"""
以下の通話内容を、次の6つのカテゴリーのいずれかに分類してください。出力は、カテゴリー名のみを返してください。
1. 商品関連
- 商品の在庫状況確認
- 商品の仕様や特徴に関する質問
- 新商品の情報やリリース予定
- 商品の返品・交換手続き
- 商品の配送状況や追跡
- 商品の不具合や破損に関する問い合わせ
- ギフト包装や特別オプションのリクエスト
2. 請求・支払い関連
- 請求書の発行や確認
- 支払い方法の変更や追加
- 支払いの遅延や未払いに関する対応
- 領収書の発行依頼
- クレジットカードや銀行振込のトラブル
- キャンペーンや割引の適用確認
- 返金手続きや返金状況の確認
3. 予約・キャンセル関連
- サービスや商品の予約手続き
- 予約内容の変更や確認
- 予約のキャンセル手続き
- キャンセルポリシーの確認
- 予約に関するリマインダーや通知
- 予約時のトラブル対応
- 予約の優先順位や特典に関する質問
4. 技術サポート関連
- システムやアプリの操作方法
- エラーメッセージや不具合の解決
- ソフトウェアやファームウェアのアップデート
- デバイスや機器の接続方法
- アカウントやログインの問題
- セキュリティやプライバシーに関する質問
- 技術的なトラブルシューティング
5. 会員情報関連
- 会員登録やアカウント作成
- 会員情報の変更(住所、電話番号、メールアドレスなど)
- パスワードのリセットや変更
- 会員ランクや特典の確認
- 会員資格の更新や解約
- ポイントやマイルの確認・利用
- 会員限定サービスやイベントの案内
6. その他
- 上記のいずれにも該当しない問い合わせ内容
通話内容: 「{conversation_text}」
出力は、上記のカテゴリー名のいずれか1つのみを返してください。余計な説明や文脈は不要です。
"""
return call_bedrock_model(prompt).strip()
def aggregate_call_reasons(bucket_name, file_keys):
category_counts = Counter()
for file_key in file_keys:
transcript = fetch_s3_file_content(bucket_name, file_key)
category = classify_reason_with_bedrock(transcript)
print(f"Conversation: {json.dumps(transcript, ensure_ascii=False)}")
print(f"Classified Category: {category}")
category_counts[category] += 1
total_count = sum(category_counts.values())
results = []
for category in CATEGORIES:
count = category_counts.get(category, 0)
percentage = f"{(count / total_count) * 100:.1f}%" if total_count > 0 else "0.0%"
results.append({'カテゴリー': category, '割合': percentage, '問い合わせ件数': count})
return results
def generate_csv_content(data):
output = io.StringIO()
writer = csv.writer(output)
writer.writerow(['カテゴリー', '割合', '問い合わせ件数'])
writer.writerows([[row['カテゴリー'], row['割合'], row['問い合わせ件数']] for row in data])
return output.getvalue()
def upload_file_to_s3(bucket_name, file_key, file_path):
s3.upload_file(file_path, bucket_name, file_key)
def lambda_handler(event, context):
prefix = generate_yesterday_s3_prefix()
file_keys = list_files_in_s3_prefix(TRANSCRIPTION_BUCKET, prefix)
if not file_keys:
return {'statusCode': 200, 'body': "前日のデータが見つかりませんでした。"}
processed_data = aggregate_call_reasons(TRANSCRIPTION_BUCKET, file_keys)
yesterday = (datetime.now(ZoneInfo("UTC")) - timedelta(days=1)).strftime('%Y-%m-%d')
output_file_key = f'DailySummary/daily_summary_{yesterday}.csv'
local_output_file = f'/tmp/daily_summary_{yesterday}.csv'
csv_content = generate_csv_content(processed_data)
with open(local_output_file, mode='w', encoding='utf-8') as file:
file.write(csv_content)
upload_file_to_s3(OUTPUT_BUCKET, output_file_key, local_output_file)
return {'statusCode': 200, 'body': csv_content}
処理の内容は以下のとおりです
- 前日の通話データの取得
- Contact LensがS3バケットに保存した前日の通話データを取得します。対象データは、日付ごとのプレフィックスを使用して特定します。
- 通話内容の文字起こしデータの解析
- 取得した通話データを解析し、通話内容(文字起こし)を抽出します。通話内容は、エージェント(AGENT)と顧客(CUSTOMER)の発言に限定して取得します。
- カテゴリー分類
- Bedrockを使用して、通話内容を6つのカテゴリー(商品関連、請求・支払い関連、予約・キャンセル関連、技術サポート関連、会員情報関連、その他)のいずれかに分類します。Bedrockの生成AIモデルを活用し、通話内容を適切に判定します。
- 集計処理
- 分類された通話内容を集計し、各カテゴリーごとの問い合わせ件数と割合を計算します。これにより、1日の問い合わせ内容の傾向を把握できます。
- CSV形式での出力
- 集計結果をCSV形式に変換し、S3バケットに保存します。保存されたCSVファイルは、後続の分析やレポート作成に利用可能です。
- ログ出力
- 処理中に、どの通話内容がどのカテゴリーに分類されたかをログに出力します。これにより、処理結果を詳細に確認できます。
Lambdaを実行してみる
EventBridge Schedulerを使用して、毎日10:00にLambdaを起動するように設定します。
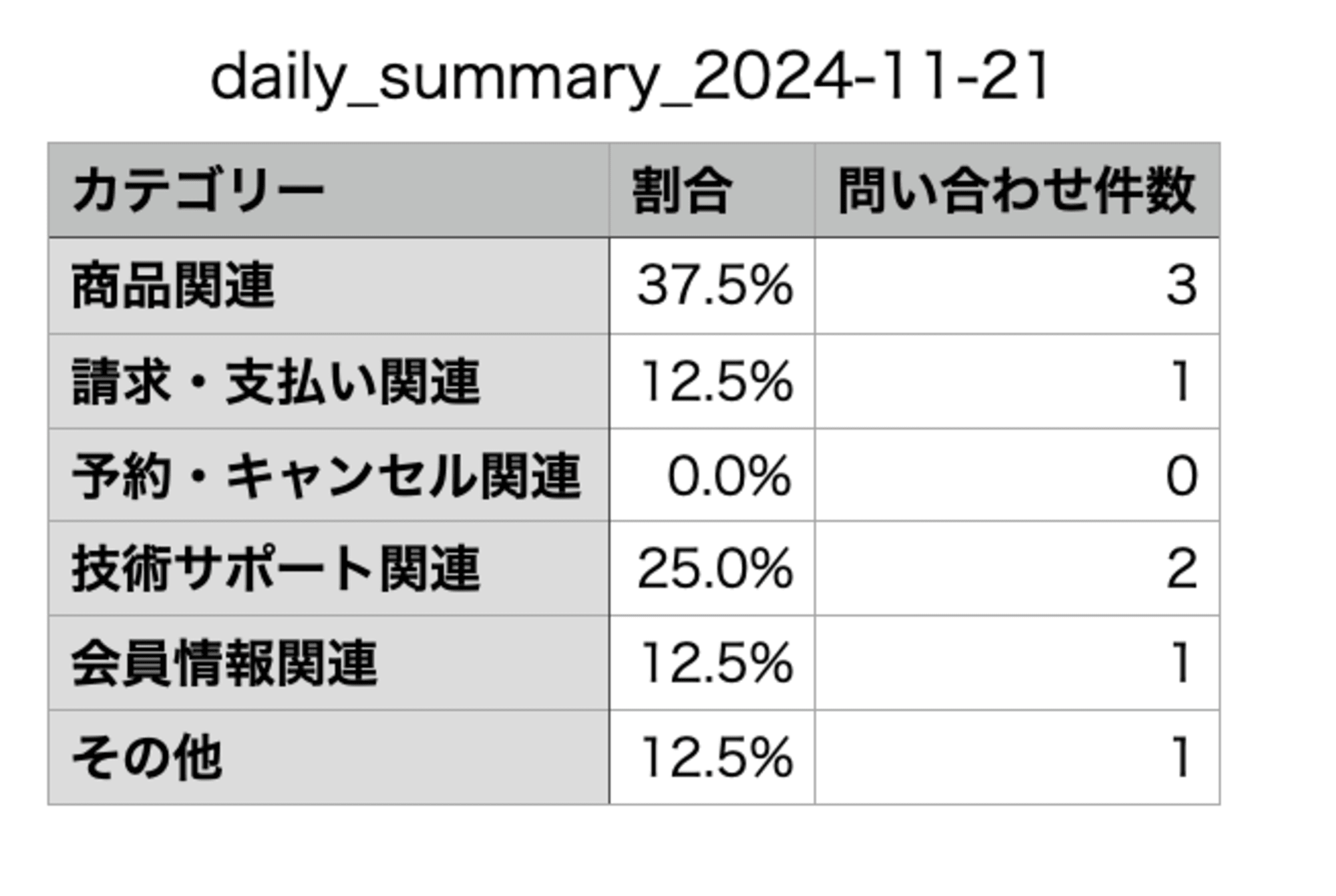
毎日、S3バケットに以下のCSVファイルが出力されます。
arn:aws:s3:::<S3バケット名>/DailySummary/daily_summary_2024-11-21.csv
カテゴリー,割合,問い合わせ件数
商品関連,37.5%,3
請求・支払い関連,12.5%,1
予約・キャンセル関連,0.0%,0
技術サポート関連,25.0%,2
会員情報関連,12.5%,1
その他,12.5%,1
ログは以下のとおりです。
どのファイルの通話内容がどのカテゴリーに判定されたかを確認できます。
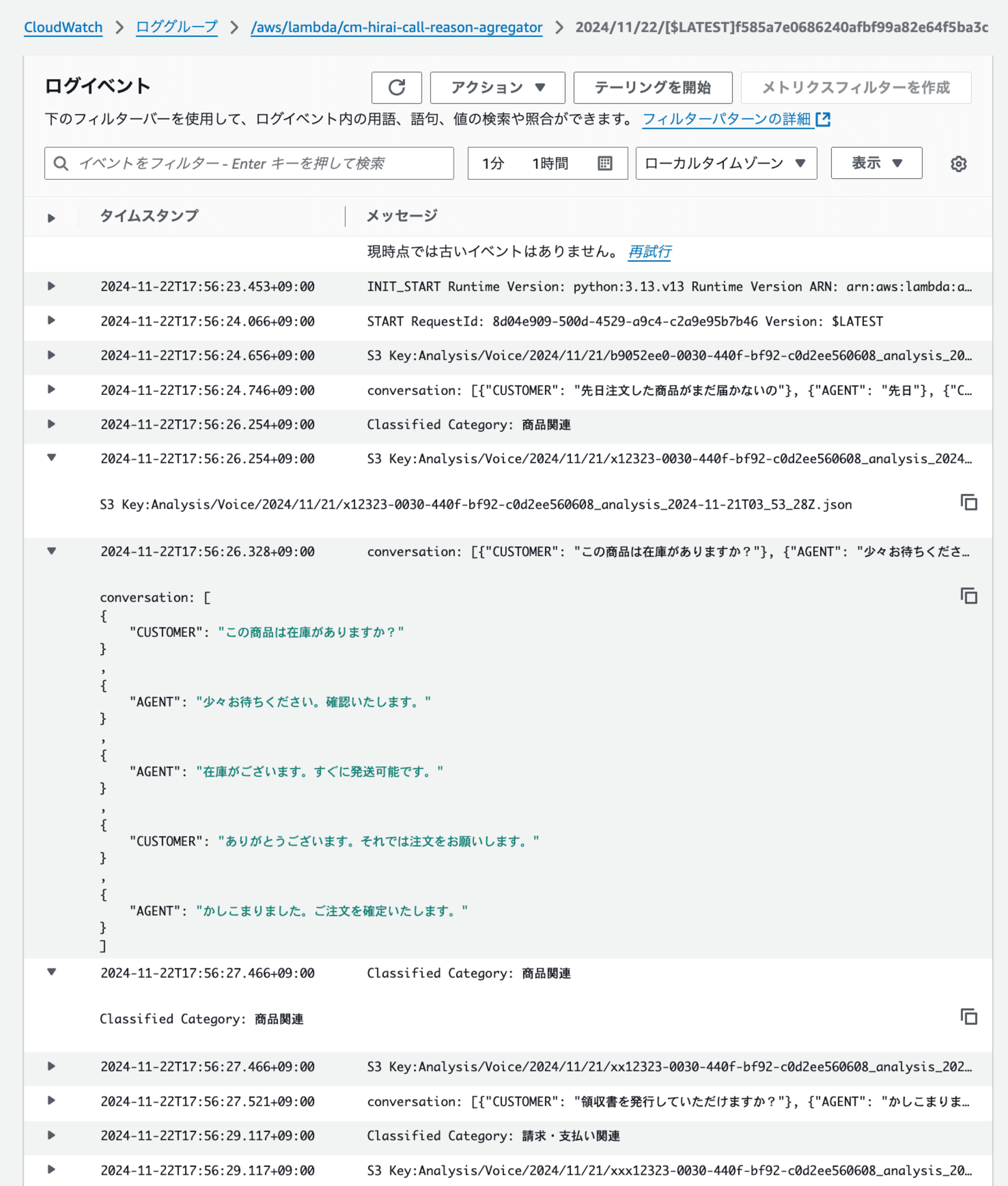
画像の実行時間は10時ではありませんが、動作確認用の実行例として掲載しています。
考慮点
本構成には、いくつか考慮点が挙げられます。
1. Lambdaのタイムアウトの可能性
毎日のお問い合わせ数が多い場合、Lambdaの実行がタイムアウトする可能性があります。
その場合、1回のお問い合わせごとにLambdaを起動し、カテゴリー判定する仕組みに変更する方法もあります。
具体的には以下のような構成が考えられます。
- Contact Lensで文字起こしファイルがS3バケットに保存されたことをトリガーにLambdaを起動し、カテゴリー判定してDynamoDBに保存します。
- 毎日Lambdaを起動し、DynamoDBのデータから、カテゴリーを集計してS3バケットにCSV出力します。
定期的にLambdaを使用してDynamoDBのデータをS3バケットにCSV形式で保存する方法については、以下の記事をご参照ください。
2. タイムゾーンの考慮
Contact LensでS3バケットに保存される際のプレフィックスは、日付ごとに分けられますが、UTCタイムゾーンが基準となっています。
そのため、Lambda関数が毎日実行される際に対象となる時間範囲は、UTCの1日(0:00~23:59)です。
これを日本時間(JST, UTC+9)に変換すると、UTCの1日(0:00~23:59)は日本時間では前日の9:00から当日の8:59に該当します。
Lambdaの実行時刻によって分析対象期間が変わります。
例えば、JST 1:00(UTC 16:00)に実行すると前々日9:00から前日8:59までのデータが対象となってしまいますが、JST 10:00(UTC 1:00)以降に実行することで、前日9:00から当日8:59までの1日分のデータを確実に分析できます。
まとめ
本記事では、Amazon Connectの通話データをAmazon Bedrockを活用して分析し、コールリーズンを自動分類・集計する仕組みを構築する方法について解説しました。この仕組みにより、問い合わせ内容を効率的に分類し、日々の業務改善や顧客対応の最適化に役立てることができます。
コールリーズンの分析は、顧客のニーズを深く理解し、サービスの向上やコスト削減につなげる重要な取り組みです。本記事を参考に、自社の業務に応用してみてください。
参考








